убрал авторизацию, обновление и создание дампа - пока вручную… с кроном еще предстоит разобратся
Но основная проблема для меня - сложные SQL запросы для сбора статистики.
Заметка в дневниках: http://www.openstreetmap.org/user/Xmypblu/diary/36289
Еще вопрос к пользователям Облако@майл.ру - там есть перечень ограничений, но в этом списке нет упоминания об ограничении количества папок и файлов.
Скажем если есть аккаунт с 1Тб хранилищем и 150-200тыс. файлов, их можно скинуть в корень или необходимо по папкам раскидать?
С папками тоже непонятно, 10-20 тыс. папок в корень хранилища - возможно?
Кто-нибудь выяснял такие ограничения?
1000 файлов в одной папке точно держит. 50 папок по 50 папок по 1000 файлов. Итого 250000.
Но, с точки зрения архитектуры, лучше делить семантически, сохраняя осмысленные имена файлов и папок.
Тем более, чт структура административно-территориального деления очень подходит для такого варианта.
Устаревшие файлы архивировать, убирать в другие хранилища и пр. Дискового пространства и мощностей никогда не бывает много.
По опыту эксплуатации подобных систем, правда без доступа к исходному коду - любое восстановление после сбоя превращается в ад, до того, что проще перезалить файлы заново.
ЗЫ На айпаде верстка поехала. Блоки друг под другом стали, а не рядом , как на скриншоте.
я бы согласился, если бы не знал, что упрусь в ограничения:
длине названия файла или папки
спецсимволы в названиях
короткие и бессмысленные названия
не уверен, но возможно и по длине URL
при загрузке на свой комп - прибавляем к пути папку сохранения
т.к. каждый файл имеет UUID, а папка помимо UUID еще и уникальный короткий номер “order_number”, планировал использовать их в качестве имен для хранения файлов/папок.
В простейшем сценарии:
сохранять все файлы в одной папке, в качестве имен использовать UUID (без расширения).
при скачивании, с помощью javascript(?) переименовывать UUID в имя файла с расширением.
т.к. дамп базы будет доступен - восстановить названия самостоятельно (локально) будет относительно просто, при необходимости
если задуматься о скачивании документов(папок)... возможно несколько вариантов.
Конечно не надо называть файлы “план современного использования и комплексной оценки территории пгт. Светлый Солнечного сельского поселения Мирного района Плодородного края Российской Федерации.pdf” как это иногда предлагает fgis.
Когда предлагал учитывать семантику, имел ввиду нечто подобное
/<код страны>/<код региона>/<название поселения>/[название нп] в пути и
<тип документа><статус><дата присвоения статуса>[_часть#из#].ext в качестве имени файла
В 255 символов должно поместиться.
Еще есть проблема. Как с мэйла получить ссылку на конкретный файл программно? API то никакого нет.
хм… надо обдумать (хотя с ходу и не нравится) и посчитать на примерах с самыми длинными названиями поселений/нп.
На данный момент более приоритетным является статистика и история изменений… но без помощи с запросами, буду долго ковыряться. Пытаюсь разобраться с терминологией postgresql, т.к. даже загуглить примеры запросов (для сбора статистики) сложно, не зная что искать.
freeExec ты в комментариях к заметке предлагал показывать дату самого нового документа в списке регионов.
Если поможешь с запросом, будет здорово - я постараюсь побыстрее внести в проект.
Наверное придется или отдельную таблицу делать или расширить atd - добавив столбец под дату.
Нагенирировать ссылок и отдачу переложить на скрипты майлру - неудобно, но как вариант… дополнительно вкладывая список фалов (txt/html) в каждую папку(документ), например.
Firebug показывает ссылки типа: _https://cloud.mail.ru/api/v2/user/space
Хотя да - официально нет и видимо не предвидится в ближайшее время, но используя бесплатные сервисы и решения - трудно ожидать скорости, удобства и логичности, что в ОСМ, что в других любых компаниях и проектах.
Так сложно что-то сказать. Неплохо бы выложить код и скрипты создания БД на гитхаб и написать какую-нибудь инструкцию по развертыванию. Думаю, помощь не заставит себя ждать
Чисто теоретически можно получить терабайт от Яндекса по цене банки Гиннеса в год. С WebDAV-ом и API. Они после окончания оплаченного периода не блокируют загрузку и не удаляют файлы. Догружать раз в полгода-год изменения, между загрузками хранить их на бесплатных аккаунтах.
Да и стоимость за год не больше оплаты дня работы программиста.
хм… я думал выложенного дампа хватит, чтобы помочь с запросами SQL
там вначале есть (для всех 3-х таблиц) “CREATE TABLE …” могу продублировать сюда, если надо.
Могу только добавить, что на OpenShift используется PostgreSQL 9.2.13
или я что-то не понимаю - и для помощи с SQL запросами, действительно необходимы исходники всего сайта?
пока продвинулся не сильно, но хоть что-то… вот например я не смог сделать одним запросом, пришлось добавить столбец
ALTER TABLE file ADD COLUMN file_ext text;
update file set file_ext=right(upper(file_name), position('.' in reverse(file_name)) -1 ) WHERE length(right(upper(file_name), position('.' in reverse(file_name)) -1 )) < 5;
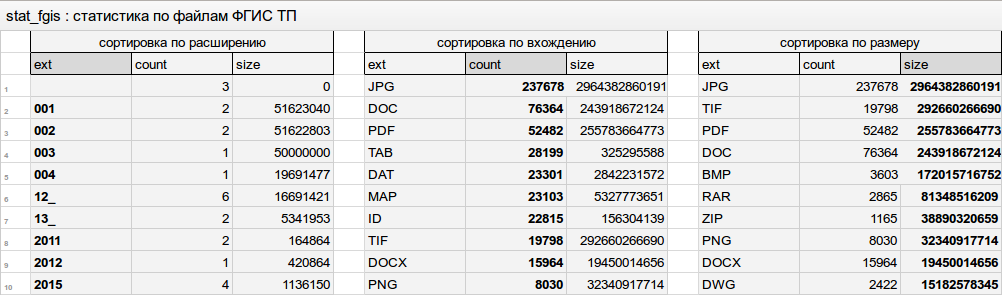
SELECT file_ext, COUNT(file_ext) AS stat FROM file GROUP BY file_ext ORDER BY stat DESC;
не хватает еще как-то вставить TRIM и в зависимости от расширения - расставить категории: архив, pdf, текстовый, растровый, векторный или векторный формат, который скачать невозможно… и можно будет рисовать графики
Восстановил базу из дампа на локалхосте.
Запрос выше можно записать без дополнительных колонок так:
SELECT (right(upper(file_name), position('.' in reverse(file_name)) -1 )) file_ext, COUNT(1) stat
FROM file GROUP BY 1 ORDER BY 2 DESC;
но:
Суммарное время выполнения запроса: 6907 ms.
207 строк получено.
Что есть очень очень плохо.
Если делать доп. колонку, то по-хорошему нужно писать триггеры на вставку/изменение с расчетом значения или вести расчет значения при загрузке на клиенте. Для этого надо ковырять код.
Еще код на github под свободной лицензией нужен для спокойствия.
Бывает, что некое ООО “РОги и нОги” выигрывает конкурс на модернизацию информационной системы некоего федерального ведомства со сроком реализации семь дней и бюджетом ХХ миллионов. Не хочется в подобном участвовать.
А помочь общему делу - завсегда, по мере возможностей.
Темпы немного упали, но теперь картина не так печальна как 2 года назад. Пусть в ОСМ не всё отрисовано, но прогресс есть и цель кажется уже не за горизонтом
Наткнулся на очень странную границу - город Инта, “почти квадрат” - http://www.openstreetmap.org/way/213129337 который захватывает другие НП. В таком виде в ОСМ существует несколько лет.