Now that 's would be transliterated the next step were the 's. I copied the code for my nodehandler changed "<node"to "<way"and "place"to "highway"and let it run. Well that did not work out. I had forgotton that ways do not contain a lat,lon.
The <nd ref=“Id” refer to nodes. Did I have to inspect these nodes? Now translit is offered xml osm data. And that contains first all the nodes and then the ways. So upon inspecting a way the info for the related nodes wis already passed.
At this time I had already my doubts if my approch of different transliterationtables for different countries was the way to go. What I had seen meanwhile while making transliterationtables for russia, romania, greece and even thailand and china that a UTF-8 character used for the cyrillic alfabet would not be used for greek or romanian or for any other.
I did not know much about charactersets but in the old sets where every character is represented by -the value of -one byte (8 bits) you need a characterset as there are only 256 values possible with a byte. So the value 198 is in cyrillic a different character as in ours.
But UTF-8 takes one to six bytes to represent a character. Our characters can be represented by one byte. I found that for cyrillic characters always two bytes are taken (found only one exception were three were needed). Greek takes two bytes too. Thai takes three and the kind of chinese (What kind is that? Could someone tell me the name?) that is used in osm takes three too.
So UTF-8 is a characterset in itself. If it is UTF-8 you are ready. (Do not laugh if you already knew: I had to find out the hard way. http://www.ietf.org/rfc/rfc2279.txt is my friend.).
Only the minor problem that the Garmin does not know UTF-8 forces to do something. And the way is not to make for instance one byte cyrillic character of two utf8 characters because the Garmin will not handle that too. The way is also not to do it in two steps: make a one byte cyrillic character of the two and then replace that with a transliteration. No you can do away with all -old- codepages. Just make one transliterationtable straight from UTF-8 to garminusable characters.
This idea could nicely be applied to the transliteration of ways. First I combined all the transliterationtables I had at that moment to one world.transliterationtable.txt.
At the moment when all tables are combined (except for the thai and chineese ones) a world transliterationtable is constructed with 339 entrys.
It was time to try it on the 's. To my joy all went like I thought it would. Program translit working on osm data that contained parts of russia, ukraina, lithuania, romania and greece transliterated all as if it had separate tables for every country.
When I saw this I realised that the algorithm used for the nodes to determine a transliteration table by means of lat,lon’s laying in country borders was superfluous.
If you click the links you will see that your browser has no difficulties displaying names which for the first half consist of cyrillic characters and for the second halfe of chinese. This is because it’s utf-8.
...
...
Above you see twice the same way. For the first the text is copy/pasted from a browser. For the second one from tekst in wordpad. (Copy/Pasting/Displaying utf-8 in different programs is a story on its own…).
Translit does not mind the combination of cyrillic and chinese and transliterates it all and adds the missing tag:
…
Edit:: well in this case adding a tag was not needed as there is already a name:en. But I found it too beautifull to not tell…
No. Not yet. As you can read the implementation changes and changes. It is in an early state of development.
It is now tested by Lambertus. The first results are not visible yet (I mean on http://garmin.na1400.info/routable.php ) . I have to spend more time on the transliterationtable(s). I first want to see that it runs at Lambertus like I want it to run.
It’s my fault that the transliterated names aren’t showing up yet. I simply forgot to add the ‘name:engels’ to the list of tags used for displaying the name. This is fixed now, but I’m running into a bug (nothing related to translit) that let’s Mkgmap crash on a lot of tiles. This has to be fixed before I’m running a new update (also, a new planet will be available tomorrow which I want to use for the next update).
I am sure the transliteration will fine in general because adding the Chinese name:zh_py worked fine as well.
It does because what counts is if a garmin device can display it.
I think a GPSmap 60Cx cannot. Well it is difficult to find out. ß in streetnames in osm are on Lambertus’ site ss. In City Navigator its only ss. That will have a reason I think.
If you have/know a small .img file with ß’s please give me a link. I’m eager to try it out.
I will spit it through but at first glance it looks to be a transliteration from two byte unicode (See the Bei Jing example on that page). But osm comes with utf8 (1 to 6 bytes). You do a conversion first from utf8 to unicode-2 before using this function?
In general the device is able to diplay all(?) latin1 characters:
But: When compiling the map, mkgmap changes all street names to uppercase
(unless you use the --lower-case option). But there is no upper case
for the “ß”, so it is converted to “SS”.
The Garmin device convertes back to lower case in the tooltips and in other fields.
If the --lower-case option is used, the street names are displayed
as A… in the map (only first letter is shown).
Chris you are talking about what mkgmap can/does. But I want to know something about the Garmin. I asked if you had/knew an .img file which contained a ß. Does not matter who put in in.
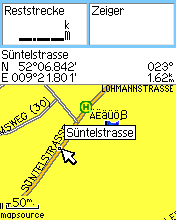
But your picture shows something very nice. Just above the Süntelstasse hint: ÄËäÜß.
Isn’t that a ß at the end? Did you type it in for a waypoint?