Хм. Ну вот я, например, умею писать иероглифы и знаю, из каких частей они состоят (достаточно, чтобы уметь пользоваться бумажным словарем по ключу). Но при своей неплохой визуальной памяти не могу запомнить строку более чем из четырех-пяти иероглифов на какое-то существенное время. Так что это не то чтобы вариант решения проблемы.
Может я чего-то не понимаю, но какое у этой проблемы (слабое знакомство русского человека с иностранными языками) может быть решение? Придумать для всех объектов в мире русские названия?
У задачи даже нет единственности решения.
Был Свеборг, потом постепенно превратился в Суоменлинна.
Для примера: вы знаете английское наименование Могилёва?
Мало того, что Ё меняется мода как передавать Ё, так, опять же, с какого языка передавать, тоже мода меняется.
Какое название нужно в каком случае — дело тонкое.
В Литве традиционные русские (древолюционные) названия (Шавли) при СССР переделали из литовских согласно неким правилам транскрипции (Шауляй).
Пришли времена новой демократии и правила поменяли (Щауляй).
Вам какое русское название Šiauliai ближе?
Для китайского языка названий на латинице недостаточно.
Названия 通江(Tōng jiāng) и 同江 (Tóng jiāng) на “чистой” латинице без пиньина неразличимы (http://fuyuan.ru/872).
А пиньин можно показать тому же китайцу и, даже не зная языка, на пальцах узнать дорогу.
У меня вопрос.
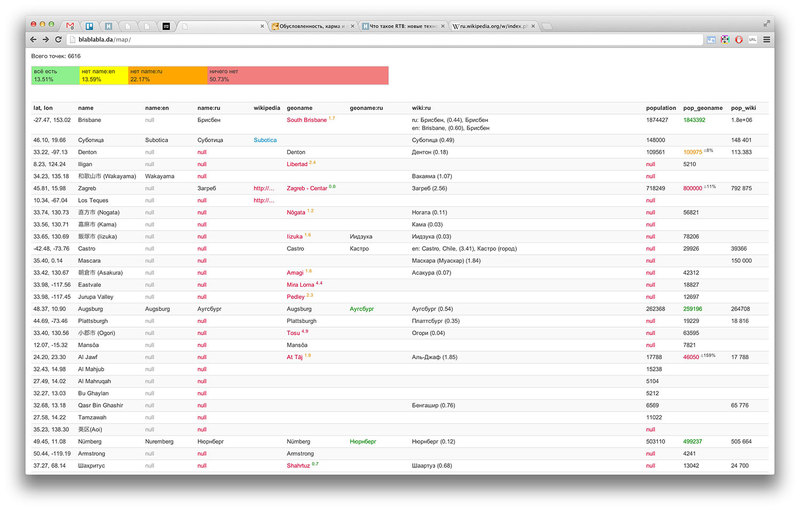
В поле name полно названий, дублированных латиницей:
直方市 (Nogata)
سنار Sennar
…
Я так понимаю, это и есть легендарное «рисование под рендер». Name:en или name_int нигде не отображается, а одни иероглифы на карте видеть — не круто.
В таких случаях латиница из этого поля должна переехать в name_int, так?
Есть устоявшиеся соглашения для регионов-стран, и не принято из вне в них влезать без явной на то просьбы. Вполне логично как-бы.
Вообще я глубоко не понимаю зачем это всё вносить в осм, раз десять описали разные люди процесс, на этапе уже после взятия данных из осм можно накатывать хоть 20 алгоритмов транскрипций какие хотите, и всё будет чуки-пуки.
Не так. От страны зависит.
Мы сейчас не про Россию - так?
Тогда стоит почитать в wiki схему наименования той конкретной страны. Например, если не ошибаюсь - в Японии вынос в name английского названия в скобках после иероглифов - местная норма.
Потому что соглашение едино, а рендеров-конвертеров сотни, со всеми не свяжешься и не договоришься. Нативно часто поддерживается всякими программами мапник только и т.п.
В базе я вижу для одной и той же страны названия латиницей в скобках, без скобок, через пробел, без пробела, через слэш, в верхнем регистре и еще несколько вариантов. Соглашение, может, едино, но бардак присутствует. Только в Японии более-менее порядок. Кроме того, «соглашение», которое описано в wiki OSM, подразумевает, что есть поля name:en и name:LN, в которых названия даны по отдельности. В жизни этого нет.
И этот бардак не разберут никакие алгоритмы транскрипции или что там еще… Для одной страны — да, можно придумать. Для всего мира — не реально.
Я постепенно убеждаюсь, что такая слабо структурированная система слабо подходит для какой-либо машинной обработки. Даже из Википедии оказалось проще распарсить данные. Там есть шаблон для описания населенных пунктов. Он описан, понятен и соблюдается достаточно строго. Ошибки и неопределенности есть менее чем в 1% случаев на 161 000 точек.
Транслитерация вещь сильно в себе. Она должна быть уникальной для каждого языка. Тут даже просто привести примеры. Вот как пишутся названия некоторых населённых пунктов на территории России и попытки их “интернализировать”.
Когда в языке-источнике используются совсем другие звуке чем в языке отображения то получаются очень странная смесь букв. И то что поймёт англичанин с трудом прочитает француз. Ведь не смотря на то что и тот и другой использует алфавит построенный на латинице все эти страшные нагромождения букв звучат по-разному. Ведь тот же Челябинск по-французски передаётся как Tcheliabinsk.
Тот же самый Вщиж в итальянской википедии называется Vščiž. А Тлюстенхабль на испанском (согласно википедии) - Tliustenjabl
Аналогично и с азиатскими языками. Не надо думать что транслитерация у англичан и русских будет одинаковой …